最新活動

「沒有特效,就不會有《阿凡達:水之道》!」一窺 Wētā FX 如何透過即時動作捕捉技術,打造栩栩如生的納美人
2022 年底上映的《阿凡達:水之道》可說是成功復甦電影產業低迷已久的票房,不僅締造超高票房紀錄,更憑著高超的視覺特效拿下諸多技術類獎項,也成功拿下 2023 年奧斯卡最佳視覺效果。日前國外媒體 befores & afters 特別專訪 Wētā FX 兩位資深視覺特效總監 Joe Letteri、Eric Saindon 與資深動畫總監 Daniel Barrett,揭開《阿凡達:水之道》背後不可或缺的精彩特效。
不斷突破特效技術的「那個男人」——詹姆斯卡麥隆
曾執導過《鐵達尼號》與《阿凡達》的詹姆斯卡麥隆,一直在追求特效技術上的突破。早在1997 年《鐵達尼號》就締造了電影特效的里程碑,全片特效鏡頭超過 500 多顆,像是電影開場鐵達尼號啟程畫面,便是利用原比例打造模型,外加 CG 效果呈現。而在碼頭周圍的群眾,則是透過分組綠幕拍攝對幾位演員,再藉動作捕捉生成數位角色,最後再合成。當 2009 年推出《阿凡達》時,更是展現多項技術和藝術上的突破,例如:動作捕捉、虛擬攝影技術與 3D 立體攝影技術等。到了 2022 年《阿凡達:水之道》,詹姆斯創立的 Lightstorm Entertainment 與 Wētā FX 再次提升了視覺效果的水準——不僅是在動作捕捉和角色方面,更多的突破是在電影中 CG 水的部分。


建造大型水槽對主要演員進行即時水下動作捕捉
先前與導演詹姆斯卡麥隆合作過《阿凡達》的 Wētā FX,這次也在《阿凡達:水之道》特效製作上達到新高度。第一是臉部骨架綁定與動畫,從混合形狀系統轉向新的肌肉拉伸系統(具有內建神經網絡)。另外,也透過動作捕捉套裝、頭盔攝影機、eyeline 系統、SimulCam 技術與即時深度合成技術,提升即時動作捕捉技術表現。

由於電影許多場戲都在水下進行,劇組還特別在 Manhattan Beach Studios 中長 120 英尺、寬 60 英尺、深 30 英尺的大型水槽中進行水下即時捕捉。而片中出現諸多不同類型的 CG 水效果,像是波浪、珊瑚礁、水下水流、氣泡等等。Wētā FX 還特別運用其公司內部模擬框架 Loki 與基於物理性的渲染器 Manuka 等其他工具研發流體模擬效果。

接著,befores & afters特別與 Wētā FX 主要特效人員討論《阿凡達:水之道》的製作過程。

以下為精彩的訪談內容:
由於本片許多場戲是在水下拍攝,在片場進行動作捕捉時,會需要解決哪些問題嗎?
Joe Letteri:實際上,動作捕捉主要是由詹姆斯創立的 Lightstorm Entertainment 團隊處理的,他們使用附有造浪器的大水箱,構建一個動作捕捉棚並將其沉入水箱,接著在水箱上方構建另一個棚,因為我們需要在水中和水外進行表演,像是片中角色會跳入水中,所以兩者必須一起執行,雖然概念相似,但實踐起來是截然不同的。
以《猩球崛起》來說,我們使用紅外線,因為它可以在很多情況下工作,且不會有雜散反射等干擾出現。但這方法無法在水下使用,因為紅色波長會在幾英尺內被吸收。所幸 Lightstorm Entertainment 團隊的虛擬製作總監 Ryan Champney 想出了一種近乎紫外線的超藍光,它在水下是超藍光,在水面上是紅外線,我們發現可以透過這種方式來追蹤到不錯的數據。

Daniel Barrett:這方法真的解決很多問題,同時也感謝演員群的支持。首先,他們得先學會如何舒適地長時間待在水下。然後,一旦他們習慣水下環境,就得在水下進行表演。
Joe Letteri:所以我們會讓演員在水面下游泳。雖然人類無法像片中礁人族適應水下那樣快速,但仍然可以獲得正確的游泳動作和浮力,而且有些表演只有在浸入水中時才有可能呈現出來,而不是嘗試以 Dry for wet 方式進行。接著,動畫團隊會著手進行一些額外的動作,建構更完整的角色表演。

就身體與臉部捕捉而言,在片場中有哪些事情是創新的?
Eric Saindon:就現場臉部捕捉來說,我們並沒有做太多新嘗試,只是轉變成兩個攝影機以獲得更好的捕捉數據,這提供更多臉部形狀和捕捉數據,像是嘴唇上的細節等等。如果要說最大的技術差異是即時深度合成,它能夠在相機中正確地分層。舉例來說,以前我們會把 A 放在 B 上,或者 B 放在 A 上,但是如果邁爾斯上校走在「蜘蛛」前面,然後又走到「蜘蛛」後面,我們以前就無法做到這一點。而有了即時深度合成,就可將角色正確地放置在空間中,並獲得正確的構圖。由於身高差異,如果上校(阿凡達形體)要出現在「蜘蛛」的後面,會導致構圖看似有點古怪。但有了新系統,導演對鏡頭內容、構圖、現場拍攝方式會有更進一步的了解。
而團隊也透過體育比賽的啟發,設計出一種新的眼線系統,當「蜘蛛」與邁爾斯上校互動時,我們會放置一個影像監視器在上校頭部位置。不僅同步演員的動作捕捉表演到 CG 角色上,也讓 飾演「蜘蛛」的演員可以清楚知道目光該看哪裡。

聊聊真人演員「蜘蛛」是如何無縫地與 CG 納美人結合在畫面上?
Eric Saindon:我認為一切都得從頭開始,就像很多時候你在綠幕上拍攝一個角色,拍攝內容大致是你認為該角色將要做的事情。在構圖方面,你可能會拍得有點奇怪,接著你必須把它放在一張卡片上,讓它符合你想要呈現的畫面。而以《阿凡達:水之道》來說,一切都是在實際片場中動作捕捉,所有演員一起經歷了整個場景,他們都知道整個過程,所以當涉及到真人表演時,演員明白那場戲是什麼,因為他早已表演過了。這也意味著導演也會知道他會得到什麼畫面,他可以看到演員們實際一起表演,這也為角色之間的互動提供了更好的構圖和時間上的安排。
Wētā FX 憑藉其臉部系統在數位角色領域做了很多,能否分享本片採用的新方法為何?
Joe Letteri:對我來說,這系統其實從製作「咕嚕」時就在使用,我們只是在努力克服限制,所以我只需要想如何解決,但實際上 Daniel Barrett 則是不得不處理它。

Daniel Barrett:多年來,我們一直使用的 FACS 系統,並非基於肌肉的系統,基本上它是一個基於臉部表面的混合形狀系統,它更多地是關於如何分解表情,以及動畫師如何組合。你可以用它做非常棒的情感表演,但你很容易偏離模型。你可以很容易地把不應該組合的東西組合起來,然後突然間你不太清楚自己的角色,接著又必須回去弄清楚來龍去脈,有時甚至得重建它。
我認為過去我們一直擅長情感上合理的工作,但我們真的希望在解剖學上更加合理,因此這個新系統使用肌肉拉伸來驅動,而不僅僅是表面。我們基本上是透過重建演員的臉部來測量臉部的肌肉拉伸,最後再將其應用於角色上。
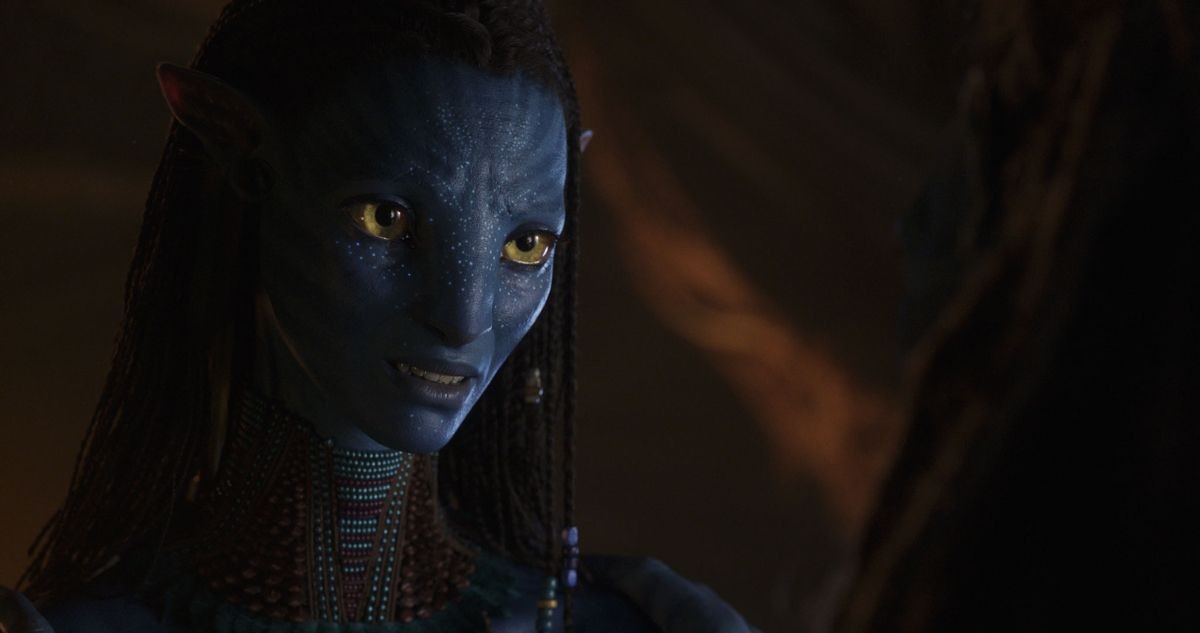
Wētā FX 一直運用深度學習和機器學習技術在臉部工具上,本片就是這種情況嗎?
Joe Letteri:我們開始在合適的地方使用它。臉部是一個非常有趣的例子,因為正如 Daniel 所說,我們想了解肌肉結構,但總不能在拍戲時即時解剖臉部,所以我們唯一能做的就是嘗試推斷它。在試圖理解肌肉結構的過程中,我意識到與建構神經網路的方式非常相似。所以我想與其嘗試使用深度學習來猜測神經網路,我們為什麼不直接告訴神經網路它要做什麼呢?這為我們提供了一種更直接的方法來接近它。
舊系統是混合變形系統,它是線性的,所以如果你想要眨眼,"0.2"將使眼睛部分閉合,"0.5"將閉合得更多,基本上是透過這些步驟來達到想要的眨眼效果。但你可以透過神經網路直接進行編碼。你可以只說睜眼、閉眼,所有動作都由神經網路處理,而不是由製作木偶的團隊處理。
舉例來說,當一個演員很多顆鏡頭被混在一起時,這會很有幫助。假設導演喜歡這裡的第一部分和這裡的第二部分,他會改變剪接點,希望以不同的節奏呈現。因此假設你使用混合變形系統,處理起來會很痛苦,兩邊眼睛會處於不同的位置,一個可能一直在向右看,另一個則一直向左看,但很明顯地這不是正確的表達方式。然而新系統允許動畫師合理地混合這些轉變,以一種更自然的方式呈現表演,這也將使動畫師可以專注於安排時間,而不是技術。
資料來源:befores & afters。文章由映 CG 所有,如需轉載請聯絡我們。

